Little Endian

There are three things that everybody encounters when learning how the
computer works: one is the difference in assembly syntax between
AT&T vs. INTEL; the other is the so-called little-endian; the third is
the two's complement representation of numbers (which I postpone to a later post).
INTEL has what I would call a vertical-view of memory with the
beginning addresses of memory at the bottom and the ending addresses at the
top.

|
| Fig. A - The vertical-view of memory. |
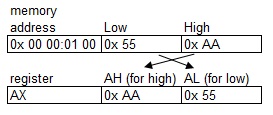
Now there are memory locations inside the CPU, and since they are relatively few you can give them a name like “John” or “Mary” or AX, BX etc. You give them a name since they are close to you as your friend or your family and you deal with them every day. In a way, you care, or they are important for you, that is why you give them a name. There are other memory locations which are outside the CPU, there are so many that we cannot remember each and every name (one would need a telephone book to assign a name to all of them); they are somehow less important for the CPU so we just count them. It is a very human way of doing things; since this piece of hardware (the PC) has been developed by humans we see some human alike patterns such the following one: we know our friends and relatives by name, they are closer and have some special meanings for us (as the registers in the CPU) and then there are the rest of other people. They influence our life as well. They are, in a different way, also important for us, but we don't care to know them by name. For instance, it is enough to know there are so and so many people in a city. So in the INTEL vertical-view of memory address 0x0000:0101 is above address 0x0000:0100, in the same way as, AH is above AL meaning that "H" is high and "L" is low. Very logical isn't it? So if we keep drawing things in this vertical-view of memory the result of MOV [0100], AX is pretty much obvious (see Fig. A). And now the funny part comes: we humans are not logical at all even if we try, so when it comes to writing things horizontally (in the way the western culture is used to, but I really wonder what would have happened if computer science were born in Japan or China where they are used to write vertically, or even in Arabia where they are used to write from right to left) then we decided that registers should be written as high-part / low-part and memory location as low-part / high-part. Crazy!!! And the result is what you see in Fig. B. It just seems that the bytes are twisted like a pretzel but it is not!
{kind=link}
{kind=link}
|
| Fig. B - The horizontal-view of memory. |
One moment, please! Who decided to write things in this way? The way you put the memory on the screen is an arbitrary decision of the programmer doing the code. If you digit d 100 within DEBUG the memory dump is presented with the convention low-part / high-part and if you digit the command r the registers are presented with the opposite convention. Now I would say this is an intellectual bug of the program which has had massive consequences. There have been CPUs designed with twisted circuitry in such a way to do things in the same twisted way our mind expects them to be, for instance: the Motorola CPUs (which are Big-Endian as opposed to the INTEL CPUs which are Little-Endian). So humans are so illogical that they find it better to design new hardware (with the relative complexity of it and the consequences on compatibility) to perform twisting in such a way that the results on the screen are in the way we like them to be, rather than changing the software that presents the memory dump on the screen (which is a relatively easy way compared to change the CPU circuitry and for sure a compatible way of doing things). We could write software in a way that the hexadecimal representation of memory is consistent rather than coming up with twisted things like Little-Endian / Big-Endian.

|
| Fig. C - The horizontal-view of memory after bug fix. |
This is human craziness! Which is absolutely beautiful if applied to fields
like literature, poetry, art, fashion, music and so on, but which can be
absolutely a nightmare if applied somewhere else in the wrong way. At this
time I realized that this journey which tries learning informatics will be a
journey throughout human madness, and if I still feel like doing it probably
I am a bit mad myself too.
Now I was a little bit unfair and maybe rude with Tim Paterson (the author
of DEBUG which is a very important software for me and I appreciate a lot
the job done by him to realize it) so let us look at things from a different
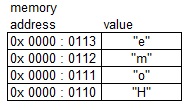
perspective: the perspective of the strings. Let us consider the string
"Home", the first letter is "H" then "o" and so on. If we write the first
letter in the first memory location and so on, we end up with the following
storage in memory:
|
| Fig. D - String in vertical-view. |
The same memory storage, in the horizontal view of memory according to Tim
Paterson displays "Home" meanwhile it displays "emoH" in the horizontal view
of memory according to myself (Fig. C). So it seems that Tim has programmed his DEBUG to have a
string-oriented-display and I would like to make one which is a
number-oriented-display. Interesting isn't it? So why not write
"Home" reversed in memory starting at address 0x0000:0113 and ending at
address 0x0000:0110? This would display "Home" in a readable way also in the
number-oriented-display proposed by me. So generally the question is
why don't we store the strings in memory in reverse order? One answer may be
that the CPU has circuitry-coded algorithms and instructions to deal with
strings (such as LODS, MOVS etc.) that work in a certain way so we have to
store strings in memory in the way the CPU is designed to handle them and
not the other way around. But one moment, the CPU has been designed to be
flexible, in fact, there is a flag called "direction flag" (and for
such a name there is a reason) which actually sets the CPU executing string
commands from low to high address in memory or the opposite way around. So
it seems that if we decide to use a convention to store strings in memory we
have to set the "direction flag" in a consistent way and both
conventions may work (at the moment this is more a hypothesis rather than a
statement and as soon as I will be able to experiment myself I will verify
it; for the moment it is a task on my personal learning to-do list).
The conclusion is that, as in every branch of engineering, there is no
perfect design, but only the best compromise among all different
requirements and targets we want to achieve with that design. Every
stakeholder has his point of view about what is the best compromise for him
so one ends up inevitably having many possible variants of the design of a
product (could it possibly be a hardware, a software, a good or a service):
this is called customization. Again you don't have to share my point of view
on little-endian but rather make your own opinion. What do you think? Let me
know in the comment.
{kind=link}
Comments
Post a Comment